Stochastic processes
Contents
Stochastic processes¶
https://www.youtube.com/watch?v=TuTmC8aOQJE
Definition: It is a collection of random variables indexed by time.
or
Definition: It is a probability distribution over a space of path (This is more helpful in further discussion).
There are two types of stochastic processes: i) continuous ii) discrete
We will focus on discrete stochastic processes here.
Let’s see some trivial examples in the context of forecasting where we have all the information about the past and we like to predict in present or future.
First example is,
import numpy as np
import matplotlib.pyplot as plt
from matplotlib import rc
from matplotlib.animation import FuncAnimation
from IPython.display import HTML
from itertools import combinations, product
rc('font',size=14)
rc('animation', html='jshtml')
t = 20
f = lambda t: np.arange(t)
plt.plot(np.arange(t), f(t), 'o-');
plt.xlabel('$t$');plt.ylabel('$f(t)$');
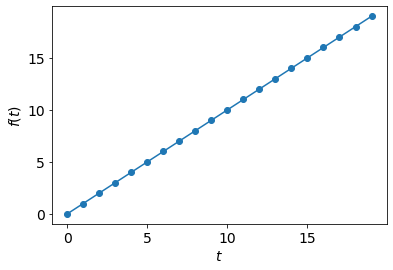
No randomness here. We are 100% certain about the value of \( f(t) \) at time \( t \).
Now, another example is,
f_possible1 = lambda t: np.arange(t)
f_possible2 = lambda t: -np.arange(t)
f = lambda t: np.arange(t) if np.random.uniform(0,1)>0.5 else -np.arange(t)
fig, ax = plt.subplots()
def frame(_):
ax.cla()
ax.plot(np.arange(t), f_possible1(t), label='possible path #1', linewidth=15, alpha=0.4)
ax.plot(np.arange(t), f_possible2(t), label='possible path #2', linewidth=15, alpha=0.4)
ax.plot(np.arange(t), f(t), 'o-', label='chosen path');
ax.set_xlabel('$t$');ax.set_ylabel('$f(t)$');
ax.legend()
plt.close()
anim = FuncAnimation(fig, frame, frames=range(t))
anim
There is a randomness in this stochastic process but once a path is chosen, we become certain. In other words, given any \(f(t),t>0\), we can know the value of \(f(t')\).
Now, yet another example,
f_possible1 = lambda t: np.arange(t)
f_possible2 = lambda t: -np.arange(t)
f_possible3 = lambda t: [i if i%2 else -i for i in range(t)]
f_possible4 = lambda t: [-i if i%2 else i for i in range(t)]
f = lambda t: [np.random.choice([-i,i],p=[0.5,0.5]) for i in range(t)]
rc('font',size=14)
fig, ax = plt.subplots()
def frame(_):
ax.cla()
alpha = 0.2
ax.plot(np.arange(t), f_possible1(t), label='possible paths', linewidth=15, alpha=alpha,color='b')
ax.plot(np.arange(t), f_possible2(t), linewidth=15, alpha=alpha,color='b')
ax.plot(np.arange(t), f_possible3(t), linewidth=15, alpha=alpha,color='b')
ax.plot(np.arange(t), f_possible4(t), linewidth=15, alpha=alpha,color='b')
ax.plot(np.arange(t), f(t), 'o-', label='chosen path',color='k');
ax.set_xlabel('$t$');ax.set_ylabel('$f(t)$');
ax.legend()
plt.close()
anim = FuncAnimation(fig, frame, frames=range(t))
anim
This stochastic process is having the most randomness, in the sense, given all the values from \(f(0)\) to \(f(t-1)\) we can not be certain about \(f(t)\).
In the study of stochastic processes, we are interested in three questions,
Given the past information, can we predict the future?
What is the long term behaviour of a sequence after observing many time-stamps?
How often boundary events (extreme events) happen? (example, stock price too high, too low)
Now, let us see the fundamental stochastic process : a simple(1D) random walk
Simple random walk¶
if \(y_i\) takes value 1 or -1 with equal probability then a simple random walk at time \(t\) is, \(f(t) = \sum\limits_{0}^{t}y_i(t)\).
f_upper = lambda t: np.arange(t)
f_lower = lambda t: -np.arange(t)
f = lambda t: [0]+np.cumsum(np.random.choice([1,-1],p=[0.5,0.5], size=t-1)).tolist()
rc('font',size=14)
fig, ax = plt.subplots()
def frame(_):
ax.cla()
alpha = 0.2
ax.plot(np.arange(t), f_upper(t), label='extreme lines', linewidth=15, alpha=alpha,color='b')
ax.plot(np.arange(t), f_lower(t), linewidth=15, alpha=alpha,color='b')
ax.plot(np.arange(t), f(t), 'o-', label='chosen path',color='k');
ax.set_xlabel('$t$');ax.set_ylabel('$f(t)$');
ax.legend()
ax.set_title('Simple random walk')
plt.close()
anim = FuncAnimation(fig, frame, frames=range(t))
anim
Let’s check for expected value and variance of \(f(t)\)
And, variance
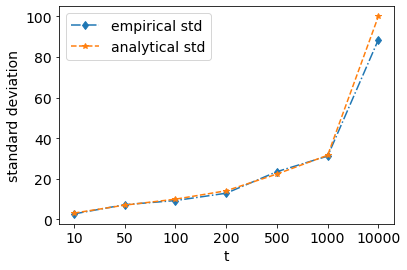
So, standard deviation would be \(\sqrt{t}\). Let us emprirically verify if this is the case.
def empirical_std(t):
return np.std([f(t)[-1] for _ in range(100)])
test_ind = [10,50,100,200,500,1000,10000]
emp_std = [empirical_std(i) for i in test_ind]
analytic_std = np.sqrt(test_ind)
plt.plot(emp_std, 'd-.', label='empirical std')
plt.plot(analytic_std, '*--',label='analytical std')
plt.xticks(range(len(test_ind)), test_ind)
plt.legend();
plt.xlabel('t');plt.ylabel('standard deviation');
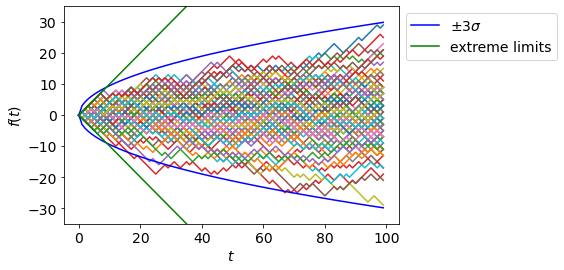
Below we show many samples drawn from a simple random walk.
t = 100
for _ in range(100):
f_t = f(t)
plt.plot(f_t);
plt.plot(3*np.sqrt(range(t)),color='b',label='$\pm 3 \sigma$');
plt.plot(-3*np.sqrt(range(t)),color='b');
plt.plot(np.arange(t),color='g',label='extreme limits');
plt.plot(-np.arange(t),color='g');
plt.xlabel('$t$');plt.ylabel('$f(t)$')
plt.ylim(-35,35)
plt.legend(bbox_to_anchor=[1,1]);
Random walk and Gaussian distribution¶
Interesting fact about a simple random walk is the following,
Let us verify this by fitting various distributions to the data.
!pip install -qq distfit
from distfit import distfit
np.random.seed(0)
t = 100000
N = 2000
samples = (1/np.sqrt(t))*np.array([f(t)[-1] for _ in range(N)])
dist = distfit(alpha=0.05)
# Search for best theoretical fit on your empirical data
dist.fit_transform(samples)['summary'];
[distfit] >fit..
[distfit] >transform..
[distfit] >[norm ] [0.00 sec] [RSS: 0.0388261] [loc=0.003 scale=1.017]
[distfit] >[expon ] [0.00 sec] [RSS: 1.4997920] [loc=-3.279 scale=3.282]
[distfit] >[pareto ] [0.16 sec] [RSS: 1.5489922] [loc=-90900135.408 scale=90900132.129]
[distfit] >[dweibull ] [0.04 sec] [RSS: 0.0551899] [loc=0.000 scale=0.872]
[distfit] >[t ] [0.08 sec] [RSS: 0.0388260] [loc=0.003 scale=1.017]
[distfit] >[genextreme] [0.08 sec] [RSS: 0.0434512] [loc=-0.367 scale=1.019]
[distfit] >[gamma ] [0.08 sec] [RSS: 0.0390275] [loc=-73.425 scale=0.014]
[distfit] >[lognorm ] [0.18 sec] [RSS: 0.0390545] [loc=-106.338 scale=106.335]
[distfit] >[beta ] [0.07 sec] [RSS: 0.0392381] [loc=-7.207 scale=13.752]
[distfit] >[uniform ] [0.00 sec] [RSS: 0.9832231] [loc=-3.279 scale=6.527]
[distfit] >Compute confidence interval [parametric]
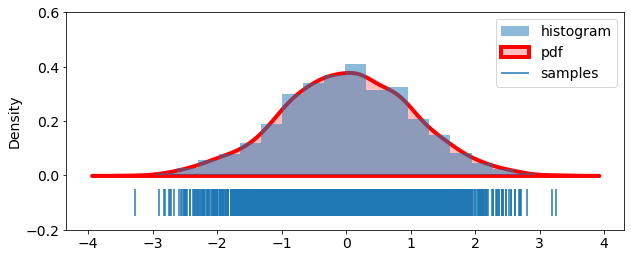
We see that for norm (Gaussian) distribution, loc (mean) is close to \(0\) and scale (standard deviation) is close to \(1\).
Let us visualize histogram and pdf of this Gaussian distribution.
from scipy.stats import norm
import seaborn as sns
samples = np.sort(samples, axis=0)
plt.figure(figsize=(10,4))
plt.hist(samples, bins=20, density=True,label='histogram', alpha=0.5);
# plt.plot(samples, norm.pdf(samples), linewidth=10, alpha=0.6, label='pdf');
sns.kdeplot(samples, shade=True, linewidth=4, label='pdf', color='r')
plt.eventplot(samples, lineoffsets=-0.1, linelengths=0.1, label='samples')
plt.ylim(-0.2, 0.6)
plt.legend(bbox_to_anchor=(1,1));